OLTP on Hadoop: 在線數(shù)據(jù)處理與交易處理業(yè)務(wù)的技術(shù)實現(xiàn)
在當今數(shù)據(jù)驅(qū)動的時代,企業(yè)對于數(shù)據(jù)處理的需求日益多樣化。傳統(tǒng)上,Hadoop生態(tài)系統(tǒng)主要用于批處理和離線數(shù)據(jù)分析,但隨著技術(shù)的發(fā)展,OLTP(在線事務(wù)處理)在Hadoop平臺上的實現(xiàn)成為可能。本文將從技術(shù)架構(gòu)的角度探討OLTP on Hadoop的實踐與應(yīng)用。
一、OLTP on Hadoop的技術(shù)基礎(chǔ)
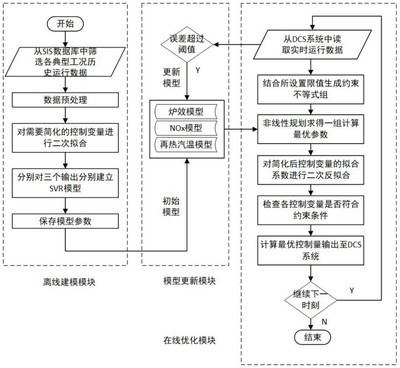
Hadoop生態(tài)系統(tǒng)最初設(shè)計用于處理大規(guī)模批量數(shù)據(jù),但其架構(gòu)的擴展性和容錯性為OLTP應(yīng)用提供了基礎(chǔ)。通過HBase、Kudu等列式存儲引擎,結(jié)合Apache Phoenix或Apache Trafodion等SQL引擎,可以實現(xiàn)低延遲的事務(wù)處理能力。這些組件共同構(gòu)成了支持ACID事務(wù)的分布式數(shù)據(jù)庫架構(gòu)。
二、架構(gòu)設(shè)計關(guān)鍵考量
實現(xiàn)OLTP on Hadoop需要解決幾個關(guān)鍵問題:首先是數(shù)據(jù)一致性,通過分布式事務(wù)協(xié)議確保跨節(jié)點的事務(wù)原子性;其次是低延遲訪問,需要優(yōu)化存儲引擎和索引結(jié)構(gòu);最后是高可用性,通過多副本和故障自動轉(zhuǎn)移機制保障系統(tǒng)持續(xù)可用。
三、典型應(yīng)用場景
OLTP on Hadoop特別適合需要處理海量交易數(shù)據(jù)且具有分析需求的場景,如金融行業(yè)的實時風控、電商平臺的交易處理、物聯(lián)網(wǎng)設(shè)備數(shù)據(jù)采集等。這些場景既需要傳統(tǒng)OLTP系統(tǒng)的事務(wù)保障,又需要大數(shù)據(jù)平臺的擴展能力。
四、挑戰(zhàn)與未來展望
雖然OLTP on Hadoop技術(shù)日趨成熟,但仍面臨一些挑戰(zhàn),包括復(fù)雜查詢的優(yōu)化、跨數(shù)據(jù)中心的同步、以及與傳統(tǒng)系統(tǒng)的集成等。隨著Apache Iceberg、Delta Lake等新一代數(shù)據(jù)湖技術(shù)的興起,OLTP與OLAP的界限正在模糊,未來將出現(xiàn)更多融合事務(wù)處理與分析處理的一體化架構(gòu)。
作為大數(shù)據(jù)技術(shù)架構(gòu)師,我們需要在保證系統(tǒng)可靠性的前提下,持續(xù)探索新技術(shù),為企業(yè)構(gòu)建既能滿足實時交易需求,又能支撐復(fù)雜分析的數(shù)據(jù)平臺。OLTP on Hadoop的實現(xiàn)正是這種探索的重要方向,它將為企業(yè)的數(shù)字化轉(zhuǎn)型提供更強大的數(shù)據(jù)基礎(chǔ)設(shè)施支持。
如若轉(zhuǎn)載,請注明出處:http://m.yuanrenyuan.cn/product/30.html
更新時間:2026-03-17 15:09:12